


中国对水产养殖水质预测预警在研究和实践层面都起步较晚,但随着水产养殖业的发展,针对水产养殖系统的水质预测预警的相关研究和探索在最近几年里发展比较迅速[7]。刘双印等[8]以水产养殖中河蟹养殖过程中的关键水质参数、DO和pH值为研究对象,采用信号处理技术、群集智能计算和机器学习技术,研究了基于计算智能的水产养殖水质预测预警方法;袁琦等[9]分别采用Matlab神经网络工具箱建立了水产养殖水环境因子pH值和DO的预测模型,其预测结果与实际值相比,平均相对误差小于1%;孙龙清等[10]提出了一种基于改进的天牛须搜索算法和长短期记忆网络相结合的DO含量预测模型;张秀菊等[11]运用BP神经网络研究了一种水质预测模型,通过对潇河流域的DO预测结果表明,BP网络能够有效地运用在水质预测方面,具有较高的预测精度和很高的实际应用价值。但是,与任何统计模型一样,BP神经网络模型也有一些缺点[12-13],如难以解释DO变化背后的机制、过多的候选因子输入会增加模型的计算复杂性以及识别最优解的难度等。因此,识别和筛选输入因子对预测DO至关重要。Reshef D N等[14]使用了一种新的变量识别方法,即最大信息系数(Maximum information coefficient,MIC),这是一种探索性分析工具,MIC用于衡量两个变量X和Y之间的关联程度[15],可以衡量两个变量线性或非线性的强度,常用于机器学习的特征选择,将输入因子经MIC识别和筛选后输入BP神经网络模型,构造一个MIC与BP神经网络融合的模型,将大大提高模型的准确度,并降低模型的计算难度。
因此,本文主要研究:1)利用MIC技术对输入因子进行识别和筛选;2)构建混合MIC-BP神经网络DO预测模型,并将其性能与独立BP神经网络预测模型进行比较;3)比较独立BP神经网络预测模型和混合MIC-BP神经网络DO预测模型性能,得到最优DO预测模型。通过构建和对比两种不同的DO预测模型,为闽江水口库区的DO精准预测提供方法指导,进而为闽江水口库区的渔业生产调控管理提供科学依据。
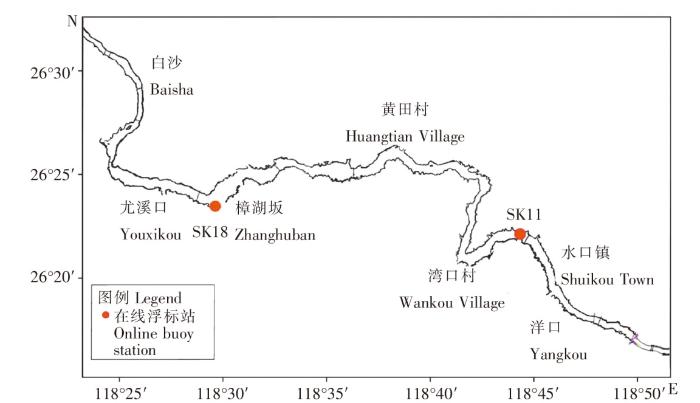
1 研究区域和数据来源
研究区域选择福建省樟湖镇和古田县的淡水水产养殖重点水域,水质数据来自两个在线浮标站位SK11、SK18,其中SK11站位(118°44'19.95″E、26°22'32.73″N)位于宁德市古田县水口镇水域,SK18站位(118°29'37.76″E、26°23'28.54″N)位于南平市延平区樟湖镇水域(图1),监测水深为0.5 m。气象数据来源于中国气象网。水质指标包括DO、水温、pH、叶绿素a、浊度、电导率、氨氮浓度和亚硝酸盐氮浓度,监测时间为2022年1月到6月,其中水温、pH、叶绿素a、浊度、电导率监测频次为1 h/次,氨氮浓度和亚硝酸盐氮浓度的监测频次为4 h/次;气象指标包括湿度、风速、风向、气压、能见度和平均总云量,监测时间为2022年1月至6月,监测频次为1 h/次。为了统一样本时间尺度,提高结果的准确性,模型构建前通过去除异常值和插值法来预处理数值因子数据,将氨氮浓度和亚硝酸盐氮浓度的频次科学地转化为1 h/次,与气象数据频次一致,统一样本数据频次。
图1
2 研究方法
图2为模型构建流程。
图2
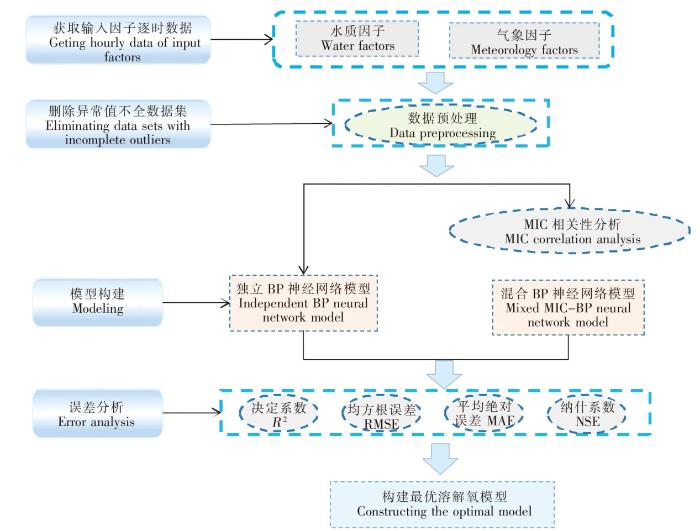
1)通过去除异常值和插值法来预处理水质因子和气象因子数据,去除对结果造成影响的异常数据并填补空缺,达到统一样本数据频次目的;
2)在经过数据预处理后,使用MIC最大信息系数对输入因子进行识别和筛选,剔除对DO影响较小的因子;
3)使用完整的数据集(未经MIC识别和筛选后的数据集)构建BP神经网络模型,进行训练,并计算模型误差;
4)使用经MIC识别和筛选后的数据集构建混合MIC-BP神经网络模型,进行训练,并计算模型误差;
5)对比分析独立BP神经网络模型和混合MIC-BP神经网络模型的误差,得出最优DO预测模型。
2.1 独立BP神经网络模型
人工神经网络无需事先确定输入与输出之间映射关系的数学方程,仅通过自身的训练,学习某种规则,在给定输入值时得到最接近期望输出值的结果。作为一种智能信息处理系统,人工神经网络实现其功能的核心是算法。BP神经网络是目前应用最多、最广泛的一种神经网络,其结构主要是多层前馈神经网络,是按照误差逆向传播算法训练出来的。这种网络结构具有对复杂数据模式进行分类和映射的能力。从网络结构上看,BP网络具有输入层、隐含层和输出层;从本质上来看,BP网络采用梯度下降法来计算目标数的最小值,然后以网络误差平方进行函数逼近,其算法称为BP算法,这种方法的特征是利用梯度搜索原理,使整个网络的最终输出结果和期望的输出结果之间的平均误差百分比的值最小。BP网络的模型结构一般由输入层、隐含层和输出层组成,其主要用于以下四个方面:
1)函数逼近:用输入向量和相应的输出向量训练一个网络逼近一个函数;
2)模式识别:用一个待定的输出向量将它与输入向量联系起来;
3)分类:采用输入向量所定义的合适方式进行分类;
4)数据压缩:减少输出向量维数以便于传输或存储。
图3显示了BP神经网络训练过程,输入信息从输入层进入后,经过隐含层变换传递到输出层,计算均方误差(MSE)。如果MSE值超过要求,则误差开始反向传递,经过隐含层传向输入层。然后调整输入变量参数再次进行训练,多次训练使MSE达到要求。
图3
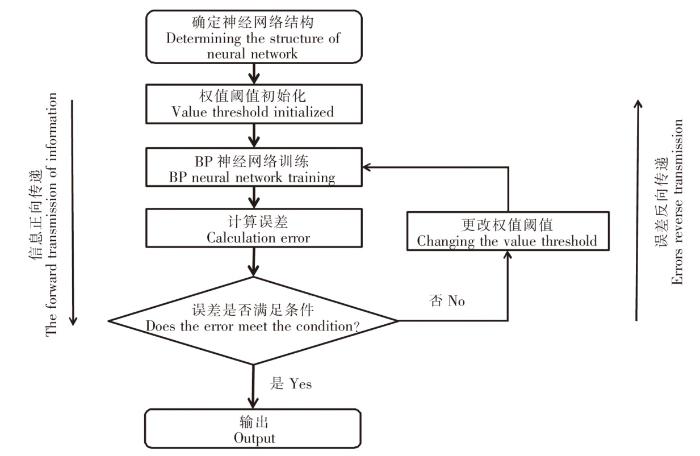
BP神经网络模型为预测DO提供了一种强大的方法,因为此类模型通常具有较高的效率,决定系数(R2)高达0.9,本研究采用了BP神经网络技术进行DO预测,利用Matlab软件中的神经网络进行机器学习,以解决环境因素和DO之间的非线性问题。
2.2 混合MIC-BP神经网络模型
水动力系统在所有的时空尺度上基本表现为非线性关系,例如最典型的温度和流量,它们表现出高度的非线性关系,而且水动力循环的相关因素之间的相互作用也十分复杂,这也决定了水动力系统中的各个因素都表现为高度非线性关系,因此这种非线性关系也几乎否决了建立输入因子与DO之间的线性关系的可能。常用的相关性分析法,如Pearson相关系数法、Spearman相关系数法和Kendall相关系数法等常用于线性数据或者简单非线性数据的分析,但若应用于非线性数据如本次DO与候选因子的数据分析,可能会造成很大的误差,影响预测的准确性。MIC是一种可以捕捉两个变量相关性的工具,不管变量之间的关系是线性还是非线性,MIC均有不错的捕捉效果。MIC的原理是若变量之间存在相关性,则可在散点图上绘制网格来划分和封装其关系,且如果变量之间是独立的,MIC值趋向于0;相反,若两变量不独立且相关,MIC值则趋向于1。
混合MIC-BP神经网络模型是将输入因子经过识别和筛选后进行训练的,有助于快速识别原始时间序列中包含的信息;BP神经网络模型则是使用所有候选输入创建了一个独立的BP神经网络模型,称为基础模型。列举基础模型是为了提供一个参考模型,从中可以比较基础BP神经网络模型和混合MIC-BP神经网络模型的结果,比较的目的是评估使用MIC方法减少输入数量后模型性能的变化。
2.3 模型评估方法
本研究使用一些被广泛认可的指标来评估所提出的预测模型的性能,包括R2、均方根误差(RMSE)、MSE、平均绝对误差(MAE)、纳什系数(NSE),这些指标计算公式如下:
式中:n是样本数;
3 结果与讨论
3.1 两站点各水质参数时间变化特征
图4
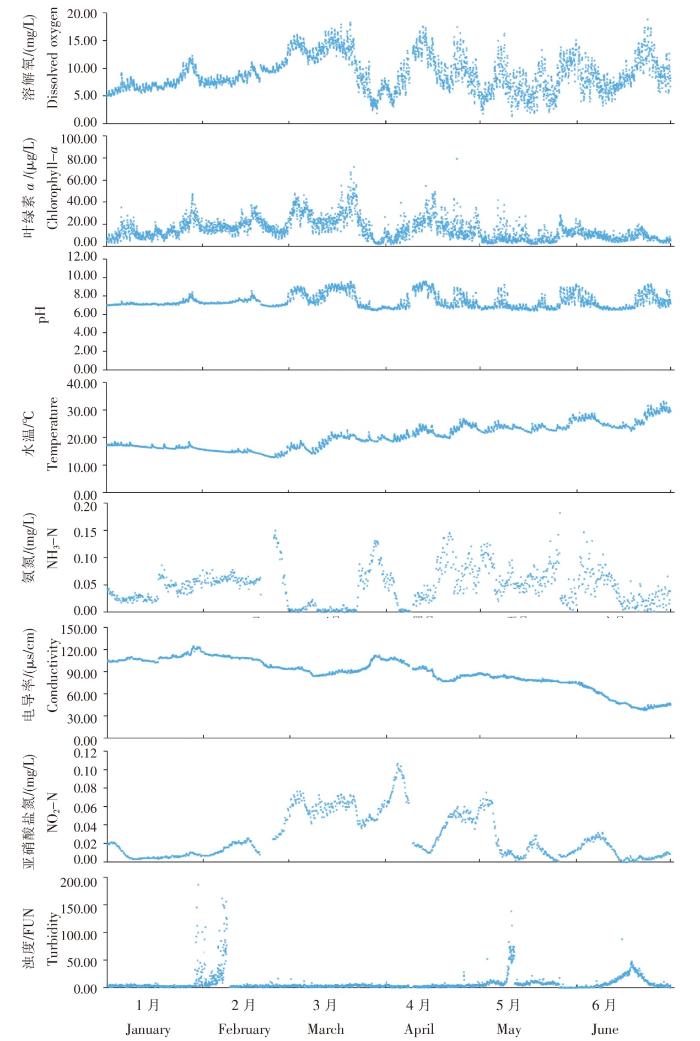
图4
SK11站位水质参数1—6月变化特征
Fig.4
Variation characteristics of water quality parameters at SK11 station from January to June
图5
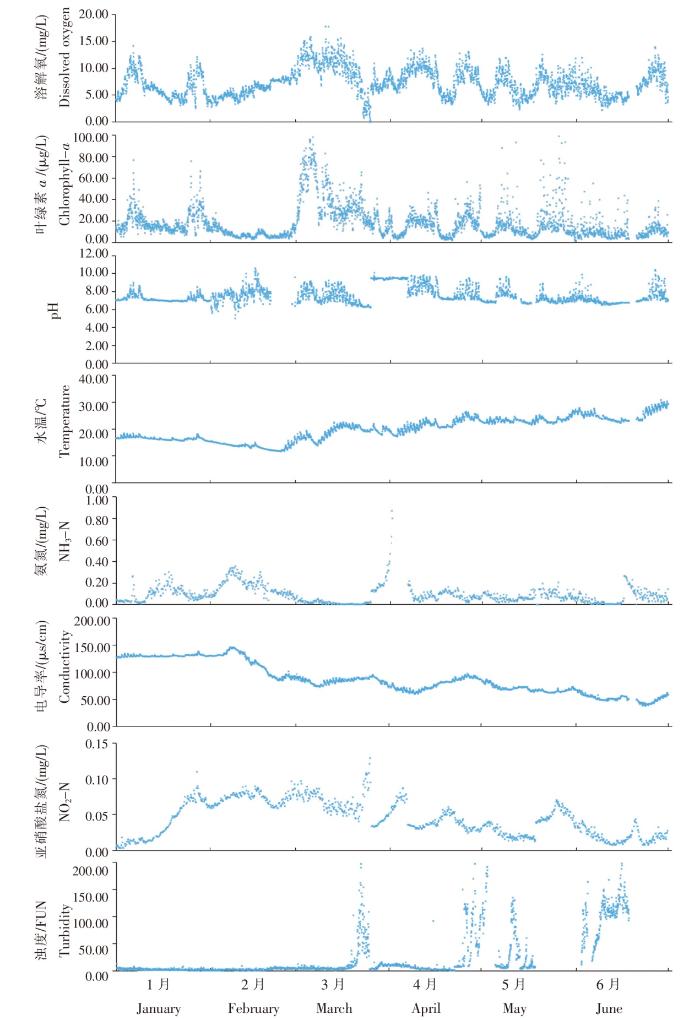
图5
SK18 站位水质参数1—6月变化特征
Fig.5
Variation characteristics of water quality parameters at SK18 station from January to June
SK11站位DO浓度区间为2~14 mg/L,叶绿素a浓度区间为3~90 μg/L,两者变化趋势相似;随着气温回暖,藻类等植物大量生长,1—3月DO和叶绿素a浓度逐渐升高,均在3月出现最高值,其中DO浓度最高为14 mg/L,叶绿素a浓度最高为90 μg/L;随后可能受降雨等因素影响,DO和叶绿素a浓度降低,但天气好转,又继而升高,总体来说,4—6月DO和叶绿素a浓度呈波动变化。pH的变化区间在6.3~8.7之间,呈弱酸弱碱性,分布较为平均,个别天数受多种因素影响而出现波动。在1—6月之间,随着时间推移,水温逐渐升高。氨氮浓度和亚硝酸盐氮浓度在1—6月分布较为杂乱,无明显规律。电导率主要与温度、悬浮物含量与水体中阴阳离子含量等有关。5—6月水温过高,导致水体电导率下降严重,其余月份水温较低,因此电导率普遍偏高。
SK18站位各水质参数时间变化与SK11大体一致,个别天数的数据因在线浮标仪器自身故障而偏离和丢失。
3.2 基于MIC的驱动输入变量识别和筛选
图6显示了SK11站位和SK18站位所有候选因子和DO之间线性和非线性关系(MIC值),数据显示:无论在SK11站位还是SK18站位,pH是对DO影响最大的因子,其与DO的MIC值在SK18站位达到了0.714 4,这与崔莉凤等[16]的研究结果一致,这主要是由于pH在水体中主要受CO2含量的影响,而CO2的含量又主要受生物过程的控制,因此pH与DO有很好的相关性;其次是水温,在SK11站位与DO的MIC值为0.411 3;湿度、风速、风向、气压和能见度与DO的MIC值均在0.1以下,说明其对DO的影响不大,因此在构建混合MIC-BP神经网络模型时可以考虑剔除;平均总云量与DO的MIC值虽然在SK11站位达到0.190 7,但在SK18站位仅为0.089 4,综合考虑,在构建混合MIC-BP神经网络模型时剔除候选因子平均总云量。
图6
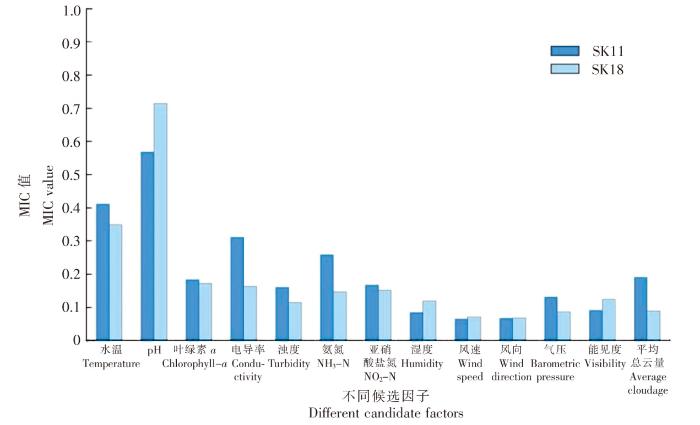
图6
SK11、SK18站位各候选因子的MIC值
Fig.6
MIC values of candidate factors in SK11 and SK18 stations
综上所述,候选因子经过MIC的识别和筛选后,在构建混合MIC-BP神经网络模型时,SK11、SK18站位的输入因子为pH、水温、叶绿素a、电导率、浊度、氨氮浓度和亚硝酸盐氮浓度。
3.3 两种模型的DO预测性能对比
独立的BP神经网络模型使用完整的数据集(未经过MIC识别和筛选后的数据集),混合MIC-BP神经网络模型使用经过MIC识别和筛选后的数据集,同时对两种模型开展机器学习,选择前70%的数据(2022年1月1日0时至2022年5月7日18时,共3 036组数据)作为样本集训练;选择后30%的数据(2022年5月7日19时至2022年6月30日23时,共1 300组数据)作为测试集来评估模型的效果。
表1显示了在SK11和SK18站位基于独立BP神经网络模型和混合MIC-BP神经网络模型的预测效果。SK11和SK18站位混合MIC-BP神经网络模型和独立的BP神经网络模型的R2平均值均为0.97,说明两种模型均具有较好的拟合效果,预测结果均有较高的可信度;混合MIC-BP神经网络模型的MAE、RMSE和NSE的平均值分别为1.05、1.76和0.62,而独立BP神经网络模型分别为1.34、2.27和0.48,对比可知混合MIC-BP神经网络模型的预测误差较小。比较两个模型的MAE、RMSE和NSE,结果表明:混合MIC-BP神经网络模型的性能相对于独立BP神经网络模型,在SK11站位:MAE降低约29.29%,RMSE降低约60.09%,NSE增加27.63%;在SK18站位:MAE降低约17.16%,RMSE降低约16.23%,NSE增加12.77%。SK11和SK18站位模拟效果见图7~图14。
表1 SK11、SK18站位模拟效果
Tab.1
| 浮标站位 Buoy station | 数据频次/h Frequency of data | 模型 Type of model | R2 | MAE | RMSE | NSE |
|---|---|---|---|---|---|---|
| SK11 | 1 | 独立BP | 0.97 | 0.99 | 2.33 | 0.55 |
| 1 | MIC-BP | 0.97 | 0.70 | 0.93 | 0.76 | |
| SK18 | 1 | 独立BP | 0.97 | 1.69 | 3.08 | 0.41 |
| 1 | MIC-BP | 0.97 | 1.40 | 2.58 | 0.47 |
图7
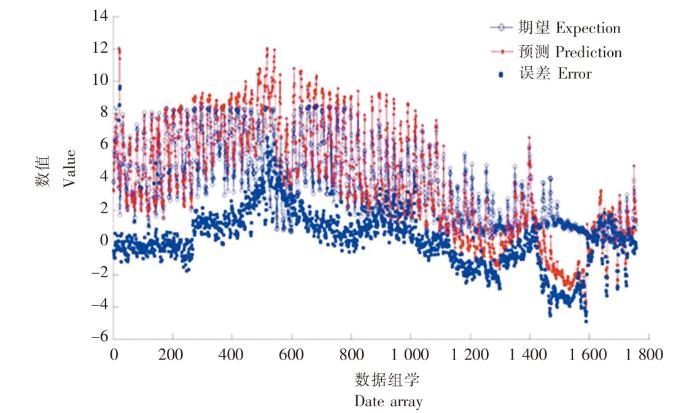
图7
SK11 站位独立BP神经网络模型拟合图
Fig.7
The fitting diagram of independent BP neural network model at SK11 station
图8
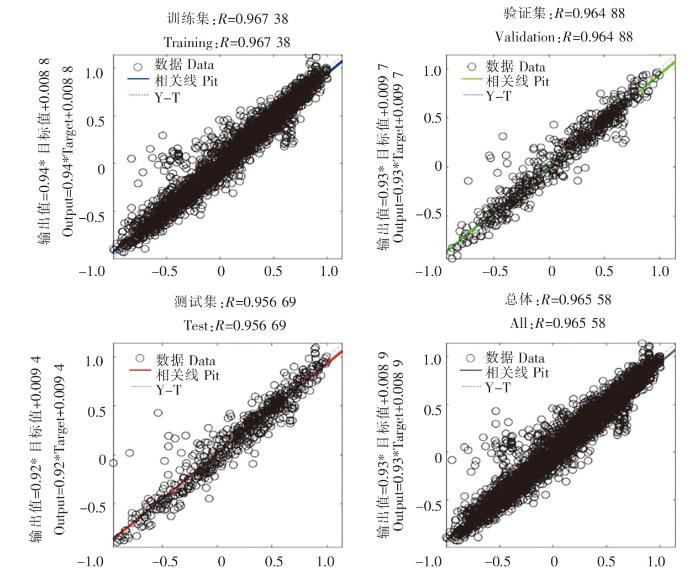
图8
SK11 站位独立BP神经网络模型的决定系数
Fig.8
The decision coefficient of independent BP neural network model at SK11 station
图9
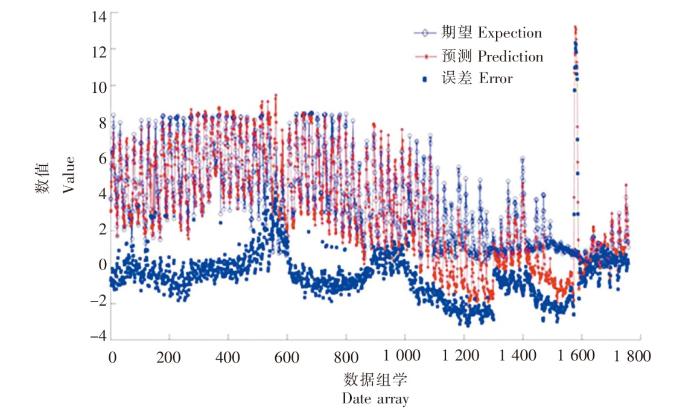
图9
SK11 站位混合MIC-BP神经网络模型拟合图
Fig.9
The fitting diagram of mixed MIC-BP neural network model at SK11 station
图10
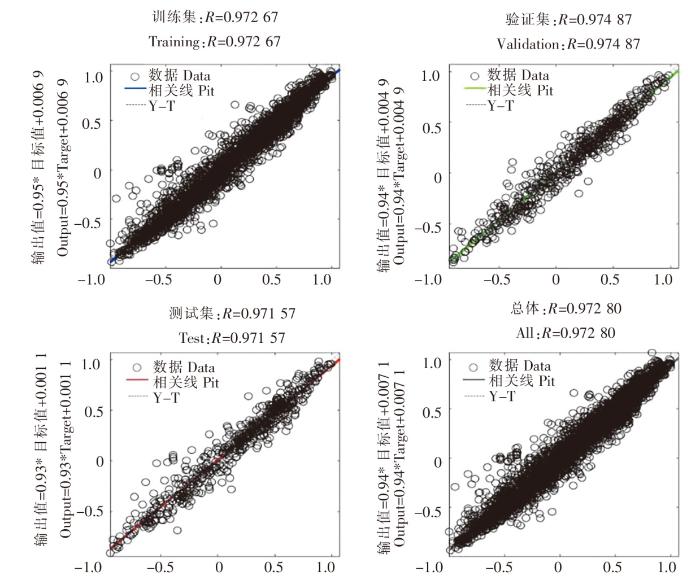
图10
SK11 站位混合MIC-BP神经网络模型的决定系数
Fig.10
The decision coefficient of mixed MIC-BP neural network model at SK11 station
图11
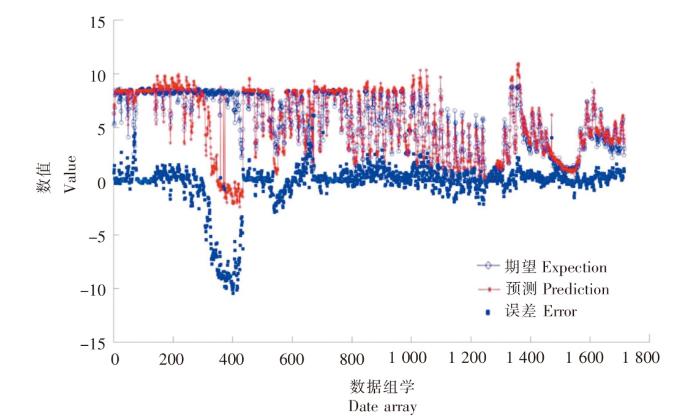
图11
SK18 站位独立BP神经网络模型拟合图
Fig.11
The fitting diagram of independent BP neural network model at SK18 station
图12
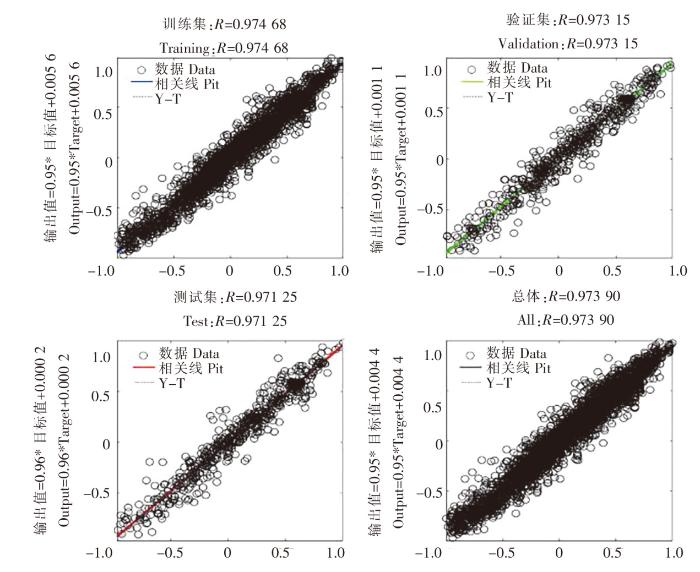
图12
SK18 站位独立BP神经网络模型的决定系数
Fig.12
The decision coefficient of independent BP neural network model at SK18 station
图13
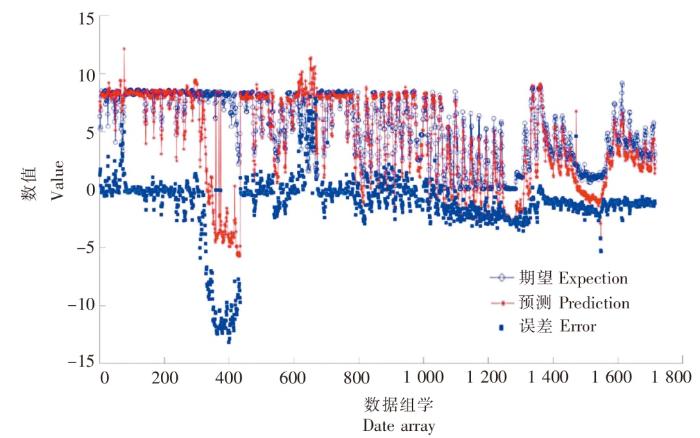
图13
SK18 站位混合MIC-BP神经网络模型拟合图
Fig.13
The fitting diagram of mixed MIC-BP neural network model at SK18 station
图14
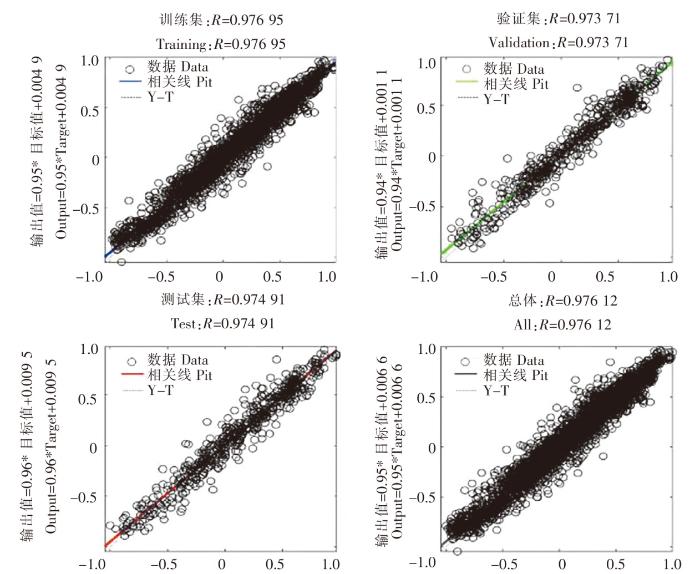
图14
SK18 站位混合MIC-BP 神经网络模型的决定系数
Fig.14
The decision coefficient of mixed MIC-BP neural network model at SK18 station
综上所述,通过对两个站位的平均误差以及各个站位不同模型的误差比较可以得出:混合MIC-BP神经网络模型的效果明显优于独立的BP神经网络模型,候选因子经过MIC的识别和筛选后可以明显提高模型的性能,因此使用混合MIC-BP神经网络模型进行DO预测得到的结果更准确。
4 结论
1)分别对SK11、SK18站位的独立和混合BP神经网络模型进行比较,发现经过MIC的识别和筛选后,模型的拟合效果和预测精度明显提升,说明MIC技术能有效筛选影响DO的主要环境因素;
2)经过MIC的识别和筛选后,混合MIC-BP神经网络模型的MAE、RMSE均得到显著的降低,NSE得到显著增大,说明基于MIC-BP神经网络模型有助于提高模型性能,更适合用于DO的预测。
总体来说,与常见的过程驱动模型、数学模型不同,BP神经网络模型属于数据驱动模型。过程驱动模型提供DO的预测是通过模拟研究区域的生化过程完成的,如硝化、反硝化和光合作用;而数据驱动模型,如BP神经网络模型,其不能完整地反映出具体的过程,但可以将现有的数据进行充分的应用,模拟出各个候选因子与DO的非线性关系,并提供DO的精准预测;与数学方法相比,BP神经网络则具有更好的稳定性和鲁棒性,能够更加快速准确地对DO进行预测,而经过MIC的筛选后,模型的拟合效果和预测精度明显提升,更适合用于DO的预测。
参考文献
珍珠龙胆石斑鱼对水温、盐度和低溶解氧耐受能力的初步研究
[J].
为研究珍珠龙胆石斑鱼对海水温度、盐度、溶解氧等主要环境因子的耐受能力,选择体质量121.4~277.5 g、体长174~229 mm、健康活泼的珍珠龙胆石斑鱼,采用渐变式方法进行试验。结果表明:珍珠龙胆石斑鱼对水温、盐度和溶解氧耐受范围较广,适宜水温为20.0~35.0℃,临界下限水温为10.0℃,临界上限水温为39.0℃;适宜盐度为11.0~40.0,临界下限盐度为3.0,上限盐度45.0;耐受低氧:窒息临界点为0.70 mg/L,DO50为0.67 mg/L,DO100为0.60 mg/L。
急性低氧胁迫对四指马鲅幼鱼鳃和肝组织损伤的影响
[J].为探究急性低氧胁迫对四指马鲅(Eleutheronema tetradactylum)幼鱼鳃器官的影响以及肝脏组织损伤情况,对四指马鲅进行了水体溶解氧为2 mg/L、时间为120 min的急性低氧胁迫试验,采用常规石蜡切片和 HE 染色以及电子显微技术,观察四指马鲅的鳃和肝脏器官。结果显示,在急性低氧胁迫下,四指马鲅鳃丝内血窦收缩、末端膨大,鳃小片长度变长、间隔变大,部分上皮细胞肿胀凸起;线粒体丰富细胞的顶隐窝由内凹变为平整,胞内线粒体形态由椭圆形变为圆形;肝组织出现肝细胞坏死、肝细胞融合等现象。表明低氧胁迫对四指马鲅鳃和肝组织具有较大的影响,且120 min就会造成组织结构的损伤。
Detecting novel associations in large data sets
[J].Identifying interesting relationships between pairs of variables in large data sets is increasingly important. Here, we present a measure of dependence for two-variable relationships: the maximal information coefficient (MIC). MIC captures a wide range of associations both functional and not, and for functional relationships provides a score that roughly equals the coefficient of determination (R(2)) of the data relative to the regression function. MIC belongs to a larger class of maximal information-based nonparametric exploration (MINE) statistics for identifying and classifying relationships. We apply MIC and MINE to data sets in global health, gene expression, major-league baseball, and the human gut microbiota and identify known and novel relationships.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}